Parsing SMILES with fnparse, Part 1
Joshua Choi's fnparse is a clojure library for creating parsers using a functional programming approach. Clojure (somewhat strongly) encourages a functional approach to programming, with immutable objects, implicit concurrency, etc... While this is a nice idea, it, at first glance, may seem hard to reconcile this with something like parsing in which one encounters a great deal of state, created by the things that are parsed along the way. In previous parsing efforts in Common Lisp I used local variables for capturing state as it was encountered, often keeping track of things in hash-tables, recording the acquired state as I went along. This was all well and good, but how was I going to take a similar approach that discourages mutable data types? Turns out that Joshua had done a lot of the thinking about how to do this elegantly and has created the fnparse library for creating functional parsers in clojure.
What are we parsing? Why, SMILES strings, of course. SMILES is a way of representing molecules, or at least the atoms, bonds, etc... that make up molecules. A simple example of a smiles string is for methane:
C
Which represents a single carbon with 4 hydrogen atoms attached to it. Not particularly exciting, but, as one might imagine, one can represent more complex atoms with SMILES as well. For instance, here's the SMILES for ibuprofen:
CC(C)CC1=CC=C(C=C1)C(C)C(=O)O
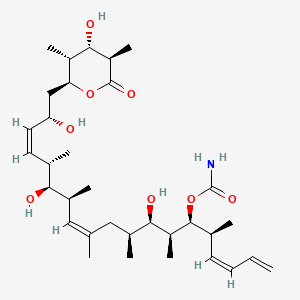
And even this is a relatively simple molecule. By comparison, to represent discodermolide, a complex natural product found in certain sea sponges, one needs a SMILES like this:
C[C@H]1[C@@H](OC(=O)[C@@H]([C@H]1O)C)C[C@@H](/C=C\[C@H](C)[C@@H]([C@@H](C)/C=C(/C)\C[C@H](C)[C@H]([C@H](C)[C@H]([C@@H](C)/C=C\C=C)OC(=O)N)O)O)O
A 2-d representation of discodermolide can be seen below:
As you can see, this is starting to get a bit complex, and the machinery that a SMILES parser, and the underlying data models used to represent this information, start to get a bit hairy. Fortunately, I've got fnparse to help me deal with some of this hair, at least on the parsing side anyway.
fnparse has a module called hound that can be used for LL(1) or LL(n) parsers. I've forgotten my compiler theory from undergrad days, but I think SMILES strings are LL. If anyone can confirm that, that would be great. In any event, my SMILES parser uses hound and I haven't run into anything that hound can't handle yet. There are a few examples where we use lexical parsing to look ahead but, other than that, the SMILES syntax is quite simple, but there's a lot of information represented by this concise format and building up the data models from a SMILES string can be a bit tricky. fnparse provides the infrastructure for writing parsers in a functional style and handles the explicit management of state via a mutable object known as the context. A few words on the current fnparse before diving into the details and some examples. First of all, Joshua has been rather majorly redoing the core fnparse API. The upshot of this is that there's a new branch called the develop branch which has this new, improved, at least in my opinion, API, and this is what I've used for chemiclj's SMILES parser. Second, as this is a work in progress, the documentation for the develop branch of fnparse is still rather limited. Fortunately, Joshua provides examples for parsing JSON files and clojure source files. The JSON example is fairly straightforward and is a great place to start, while the clojure example is a bit more complicated and (until at recently, anyway) makes heavy use of contexts. More on contexts memontarily.
Oh, heck, more on contexts now. Well, almost, first lets discuss the general structure of an fnaprse parser. For an LL parser we can use hound and the entry is a method called match. match takes 1) the initial state of the parser, which includes the input which we are going to parse, and, optionally, other data, 2) a "rule" to match to the input data, and 3) optional functions to be called on success or failure. That's simple enough, but, clearly, that puts the hard work in the hands of the rules. What are rules? Well, here's where hound comes in to give us the infrsastructure for LL parsers. We can either use built-in rules like h/lit (I'm using the h/ prefix for hound symbols), for instance to match a left-bracket we could use the rule (h/lit [). Of course this isn't all that interesting. If we were just parsing simple literals, we wouldn't need all of this machinery. It starts to get more interesting when we start making our own rules. The simplest way to make a rule is with the h/defrule function. For instance, the following creates a rule to match the symbol for a double bond (the = symbol) and to return the constant value 2 when this is encountered:
(h/defrule <single-bond> (h/chook 1 (h/lit \-)))
Again, this isn't yet all that interesting, but as we add more rules, and add other more powerful rules besides just those to match literals, things get interesting indeed -- at least as far as SMILES strings can be considered interesting, in this case. The h/+ rule can be used to match any one of a list of items, the h/cat rule can be used to match a sequence of multiple items, etc... Let's take a look at a more complex example from the SMILES parser. The following code snippet is for parsing bracket expressions in SMILES. I'll spare you the details of what exactly these are, other than to say that they are for representing more complex atoms than the simple organic atoms, carbon, nitrogen, oxygen, phosporus and sulfur, with the usual charges. If one wants to represent a Silicon atom, one needs to use [Si], or a charged atom like a sodium ion can be represented by [Na+]. Part of the code for parsing these bracket symbols is shown below:
(defn str* [objects]
(apply str objects))
(h/defrule <left-bracket> (h/lit \[))
(h/defrule <right-bracket> (h/lit \]))
(h/defrule <bracket-aliphatic-element-symbol>
(h/hook (comp str* concat)
(h/cat h/<uppercase-ascii-letter>
(h/opt h/<lowercase-ascii-letter>)
(h/opt h/<lowercase-ascii-letter>))))
(h/defrule <bracket-aromatic-element-symbol>
(h/for [symbol (h/+ (h/hook (comp str* concat) (h/cat (h/lex (h/lit \s)) (h/lit \e)))
(h/hook (comp str* concat) (h/cat (h/lit \a) (h/lit \s)))
(h/hook str (h/lit \c))
(h/hook str (h/lit \n))
(h/hook str (h/lit \o))
(h/hook str (h/lit \p))
(h/hook str (h/lit \s)))
_ (h/alter-context
(fn [context] (assoc context :aromatic true :hybridization :sp2)))]
symbol))
(h/defrule <bracket-element-symbol>
(h/label "a bracket element symbol"
(h/+ <bracket-aliphatic-element-symbol> <bracket-aromatic-element-symbol>)))
Here we see Joshua's convention of naming rules with surrounding angle-brackets like <bracket-element-symbol>, but, more importantly, we start to see what these rules are doing. Let's take a look at <bracket-aliphatic-element-symbol>:
(h/defrule <bracket-aliphatic-element-symbol>
(h/hook (comp str* concat)
(h/cat h/<uppercase-ascii-letter>
(h/opt h/<lowercase-ascii-letter>)
(h/opt h/<lowercase-ascii-letter>))))
<bracket-aliphatic-element-symbol> is a rule that is designed to match aliphatic atoms, that is atoms that are not aromatic -- we need to make the distinction as this changes the interpretation of the kind of (default) bonds connecting this atom to other atoms. The aliphatic atom will be represented by the symbol for the appropriate element, an initial capital followed by 0, 1 (or 2 for the really heavy atoms in the periodic table) lowercase letters completing the elemental symbol. The first subrule encountered is actually a sort of metarule. h/hook is a function which is going to make a rule for us, based on the arguments we provide it. In fnparse terminology, h/hook is a maker. Maker's are defined by fnparse's defmaker macro, but we're getting a little ahead of ourselves. Let's go back to the h/hook example. The arguments to the hook maker are [semantic-hook rule] and if rule is successfully matched, semantic-hook will be called with the results of matching rule. In this case we'll call (comp str * concat) on the results of the h/cat rule. (comp str * concat) returns a function that will first concatenate it's args and then apply the str function to the arguments. The h/cat form is a maker that returns a rule that will match each of the provided rules in sequence. Here, we need to match an uppercase letter and then two optional lowercase letters. Notice that hound is smart enough to match a lowercase letter if one is present, but otherwise it doesn't consume a token. We'll cover other cases where we need to be more explicit about backtracking shortly, but for the rule at hand, hound handles all of this for us.
Looking at the rule for aromatic atoms expressed in atoms, we see an example of where we need to use h/lex to allow for backtracking in the event of a partial, but ultimately undesired match:
(h/defrule <bracket-aromatic-element-symbol>
(h/for [symbol (h/+ (h/hook (comp str* concat) (h/cat (h/lex (h/lit \s)) (h/lit \e)))
(h/hook (comp str* concat) (h/cat (h/lit \a) (h/lit \s)))
(h/hook str (h/lit \c))
(h/hook str (h/lit \n))
(h/hook str (h/lit \o))
(h/hook str (h/lit \p))
(h/hook str (h/lit \s)))
_ (h/alter-context
(fn [context] (assoc context :aromatic true :hybridization :sp2)))]
symbol))
Notice that in the expression:
(h/cat (h/lex (h/lit \s)) (h/lit \e)))
We have to use h/lex around the (h/lit \s) form. This is because we want to match se (for selenium), but if we don't see that, we also want to be able to match s for sulfur, so once we've made the match for the \s, we need to basically back up the parser if we still want to match that same \s elsewhere.
Ok, enough of the gory details, let's skip ahead to an example to see how we would actually parse a SMILES string, then we can come back to more of the gory details:
user> (require ['chemiclj.smiles :as 'smiles])
nil
user> (def alanine (smiles/read-smiles-string "CC(C)C(C(=O)O)N"))
#'user/alanine
In this case we require the smiles namespace, refer to it as smiles and then call smiles/read-smiles-string on the appropriate string and squirrel away the result in a global variable. We can write this string back out with:
user> (smiles/write-smiles-string alanine)
"CC(C)C(N)C(=O)O"
You'll notice that these two strings aren't quite the same. It turns out that there are many identical SMILES strings that can yield the same molecule. There are algorithms for attempting to generate a "canonical" SMILES string from a given molecule, but they all seem incomplete and at odds with one another. Again, more on the trials and tribulations of trying to generate canonical SMILES later. For the moment, just notice that the input and output strings are different, yet they represent the same molecule -- in this case the amino acid alanine.
That's enough for tonight. Check out chemiclj if you're interested in cheminformatics and clojure, and check out fnparse if you have other file parsing needs -- at least if you need to parse files that aren't in a format for which their already existing parsing tools such as XML, and check back for more installments in the near future. Enjoy.
--